Correct table indexing in SQL Server is a base for good database performance during querying. You need to understand how SQL Server stores data into tables/indexes if you want to create appropriate sql indexes. It is also important to know how to approach these data correctly during querying.
How Does SQL Server Organize Data Physically?
File page is the smallest unit for reading and writing into db objects in SQL Server. Every single sql file page haves 8 KB and is related to one object (for example table or index). Individual file pages are organized into Extents. Each extent consists of 8 file pages.
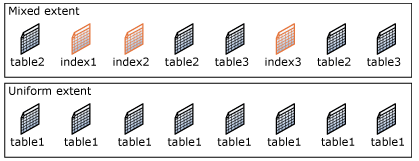
On the highest level, data are organized into 2 file types. We will focus on the first one (MDF) in this article
- MDF files where the data is
- LDF files of transactional log
Key to Understanding SQL Indexes? Logical Data Organization in SQL Server.
The way of physical data storing on disk was mentioned in the introduction. Now we finally get to the logical organization. Data are stored in file pages as was already mentioned. There is plenty of them and so there must be a system by which SQL server orientates in it.
Performance of SQL queries depends directly on ability of SQL engine to give out individual file pages to some table which we are trying to query. This performance depends on how are the tables logically organized.
We use special system objects called Index allocation map (IAM) for these purposes. Each table haves assigned at least one such object. These objects work on linking principle – it links individual file pages with tables. According to number of IAM in a table, we distinguish 2 organization methods – Heap and balanced tree
Heap – Not Organized Data
Heap means tables which are not organized in any way :) and have only 1 IAM (so called first IAM). It is like going for a book to the library which is completely unorganized. You would have to go through all the books to find the one you are looking for.
You will get a table of this type whenever you create it without the primary key or without indexes. It is simply a heap of unorganized file pages. SQL server must scan whole heap if we query such table with a condition or try JOIN with another table. This means every page file is scanned separately – and this takes a long while.

Balanced Tree – Organized Data
On the other hand, data organization such as balanced tree is something completely different. Table gets organized as a balanced tree anytime you create clustered index (i.e. primary key) above the table.
This architecture creates clusters and therefore is the scan for the records much faster. SQL Server does not have to scan whole table as in heap case. It searches individual clusters. Sql indexes therefore work like if you search library for books by genre and author.
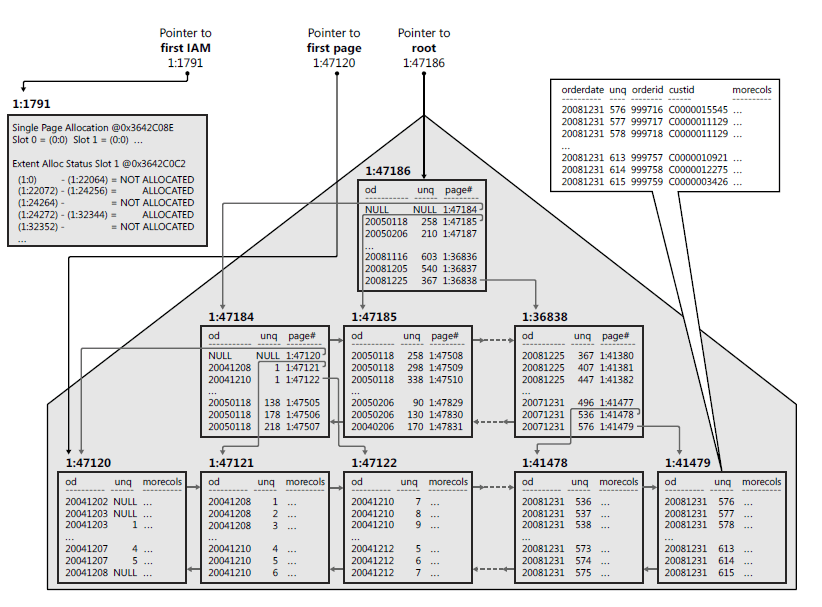
Next articles will have me look at index fragmentation and I will also demonstrate, how to repair indexes automatically using SQL script